

OpenAI has expanded its Sora AI video app to Android, bringing prompt-based video generation, Cameos, and remix...
AI & ROBOT

Adobe’s Firefly mobile app brings AI image and video creation to iOS and Android, with Creative Cloud...
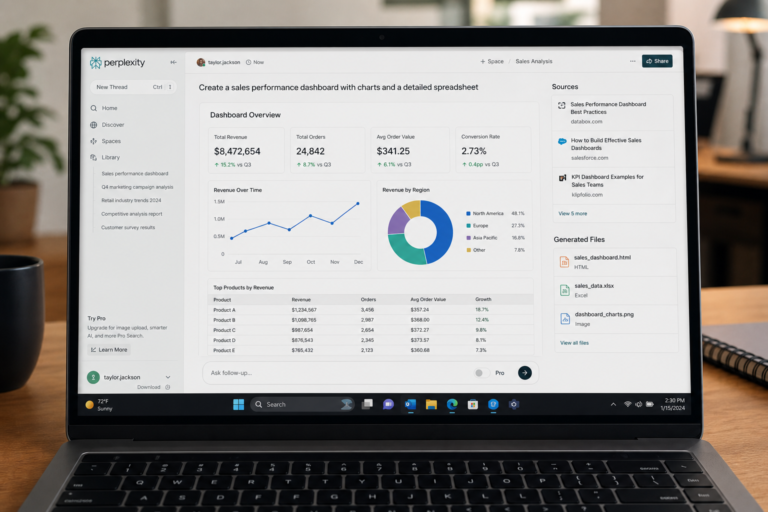
Perplexity Labs gives Pro subscribers a way to turn prompts into reports, spreadsheets, dashboards, and small web...
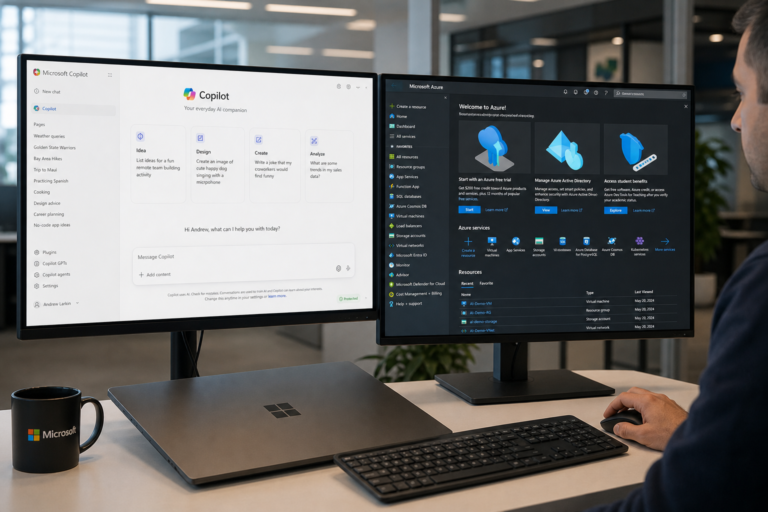
Microsoft's late-May AI update highlights a steady push across Azure AI, Copilot integrations, and developer tooling. The...
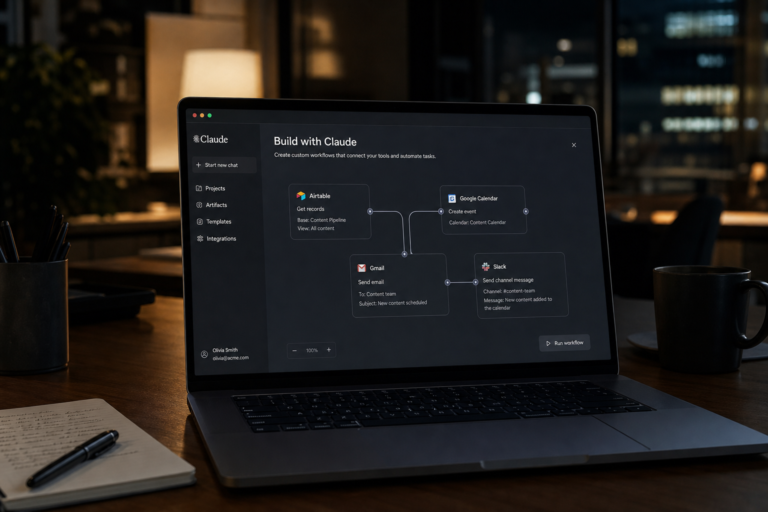
Recent AI update coverage around Claude points to a shift from chat responses toward no-code workflow building...
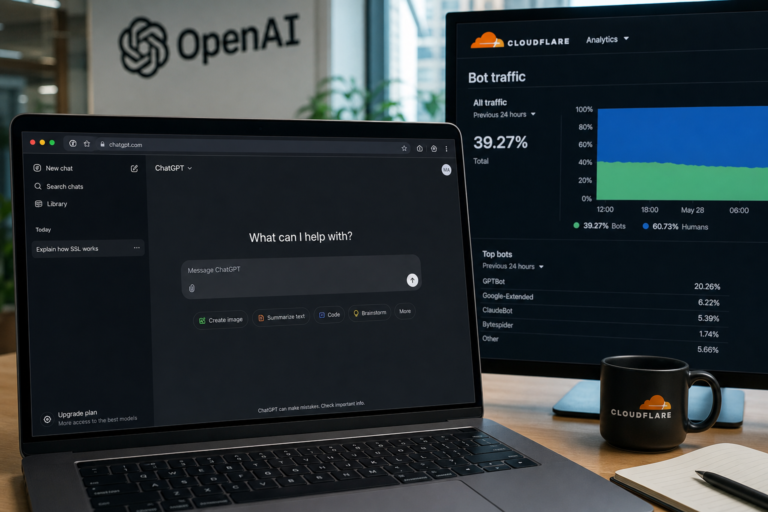
ChatGPT has reportedly crossed 1 billion monthly active users, while cited Cloudflare data shows automated systems now...
The White House used Police Week to emphasize support for law enforcement, but its latest public-safety messaging...

South Carolina’s Supreme Court unanimously overturned Alex Murdaugh’s 2023 murder convictions, citing improper juror contact by former...

Today’s supplied search results did not contain a verifiable AI news item. The available material covered Alex...

BBC investigation reveals AI chatbots linked to user delusions, sparking ethical concerns.